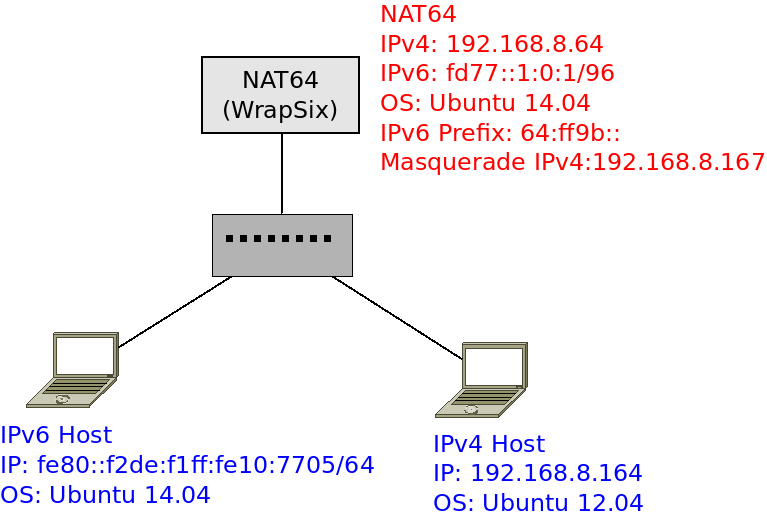
libpcap 使用範例
最近因為工作上的需求,所以透過 libpcap 寫了一個小程式。程式紀錄在下面。應該不難懂,所以就不多做說明。程式主要參考 sniffex ,不過主要針對 DHCP 的封包進行攔截以及顯示。 #include #include #include #include #include #include #include #include #define SIZE_ETHERNET (14) #define SIZE_UDP (8) #define ETHER_ADDR_LEN (6) const char *DHCP_MSG_TYPE_STR[9] = { "None", "DHCP Discover", "DHCP Offer", "DHCP Request", "DHCP Decline", "DHCP ACK", "DHCP NACK", "DHCP Release", "DHCP Inform" }; struct sniff_ethernet { uint8_t ether_dhost[ETHER_ADDR_LEN]; /* destination host address */ uint8_t ether_shost[ETHER_ADDR_LEN]; /* source host address */ uint16_t ether_type; /* IP? ARP? RARP? etc */ }; struct sniff_ip { uint8_t ip_vhl; /* version << 4 | header length >> 2 */ uint8_t ip_tos; /* type of service */ uint16_t ip_len; /...